Aprendizado de Máquina[1][2]
Introdução
Aprendizado de máquina é o campo de estudo que dá aos computadores a habilidade de aprender a resolver um problema sem ser explicitamente programado.
Vamos dizer, por exemplo, que você queira fazer um filtro de spam. Uma possibilidade é você fazer um programa utilizando técnicas de programação tradicional (sem usar aprendizado de máquina)
Como que você faria um programa tradicional para filtrar spam?
-
Você primeiro identificaria características de um spam
-
Escreveria um algoritmo para verificar se um email tem as características do spam
-
Testaria seu programa repetindo os passos anteriores até que esteja satisfatório.
O processo seria como na figura abaixo
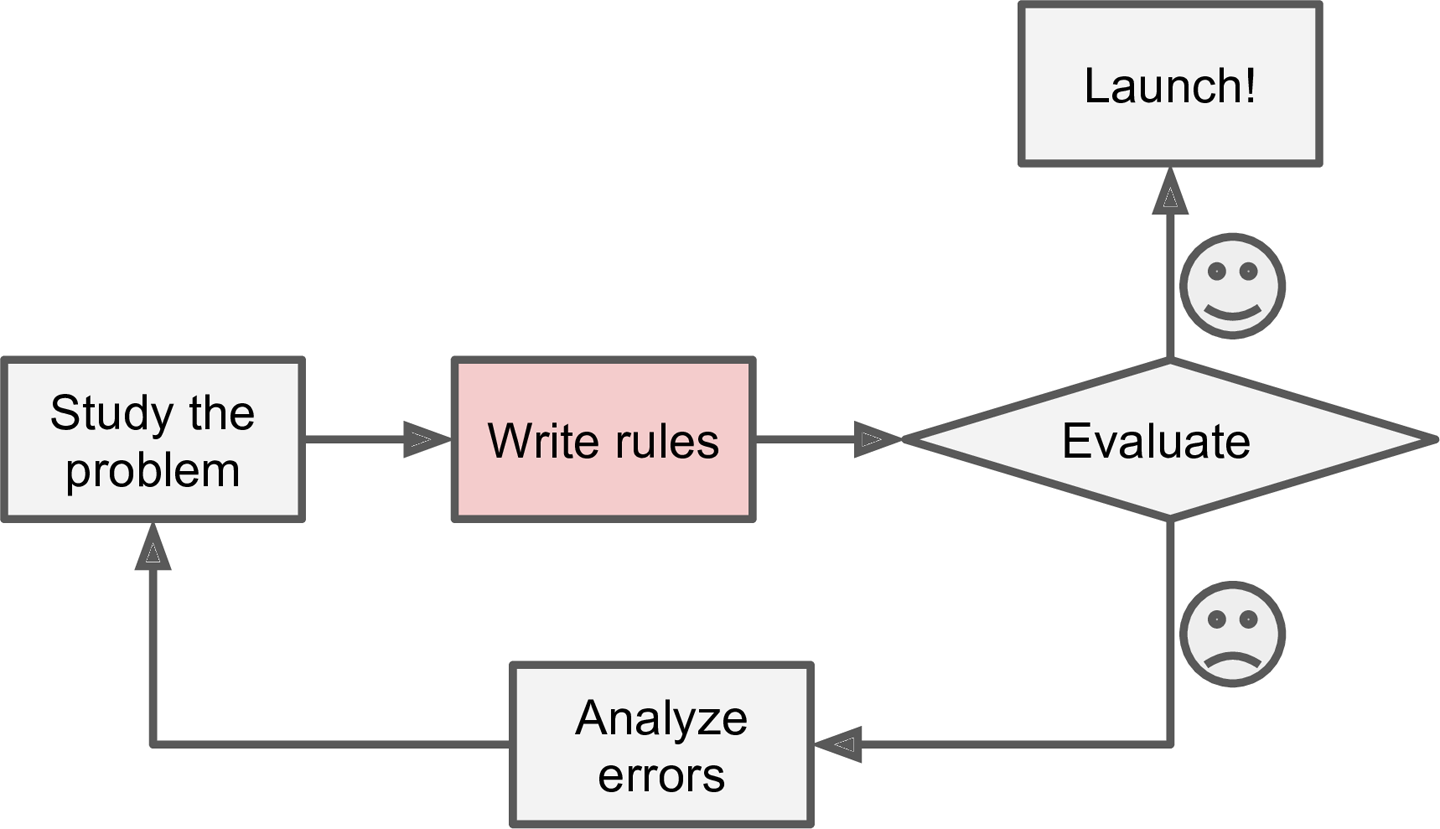
Processo tradicional para fazer um filtro de spam
Como resultado você terá uma longa lista de regras, que precisará de manutenção constante, pois sempre surgirá novos tipos de spam.
Agora suponha que você use aprendizado de máquina para resolver o seu problema:
-
Pegue uma longa lista de dados (emails normais e emails marcados como spam).
-
Separe uma parte do conjunto para treino e uma parte para teste.
-
Treine seu programa para separar emails normais de spam usando o conjunto de treino.
-
Teste seu programa no conjunto de teste.
-
Repita os passos anteriores até que seu programa esteja satisfatório.

Com a técnica de aprendizado de máquina percebemos uma mudança de abordagem.
Agora, se as caracteríscias do spam mudar, não precisamos mais reescrever, ou adicionar linhas ao nosso algoritmo. Precisamos apenas treinar o mesmo algoritmo.
Melhor ainda, podemos deixar que os usuários alimentem o algoritmo em tempo real, marcando emails como spam. Assim o mesmo algoritmo poderá sempre estar sendo treinado com novos dados.
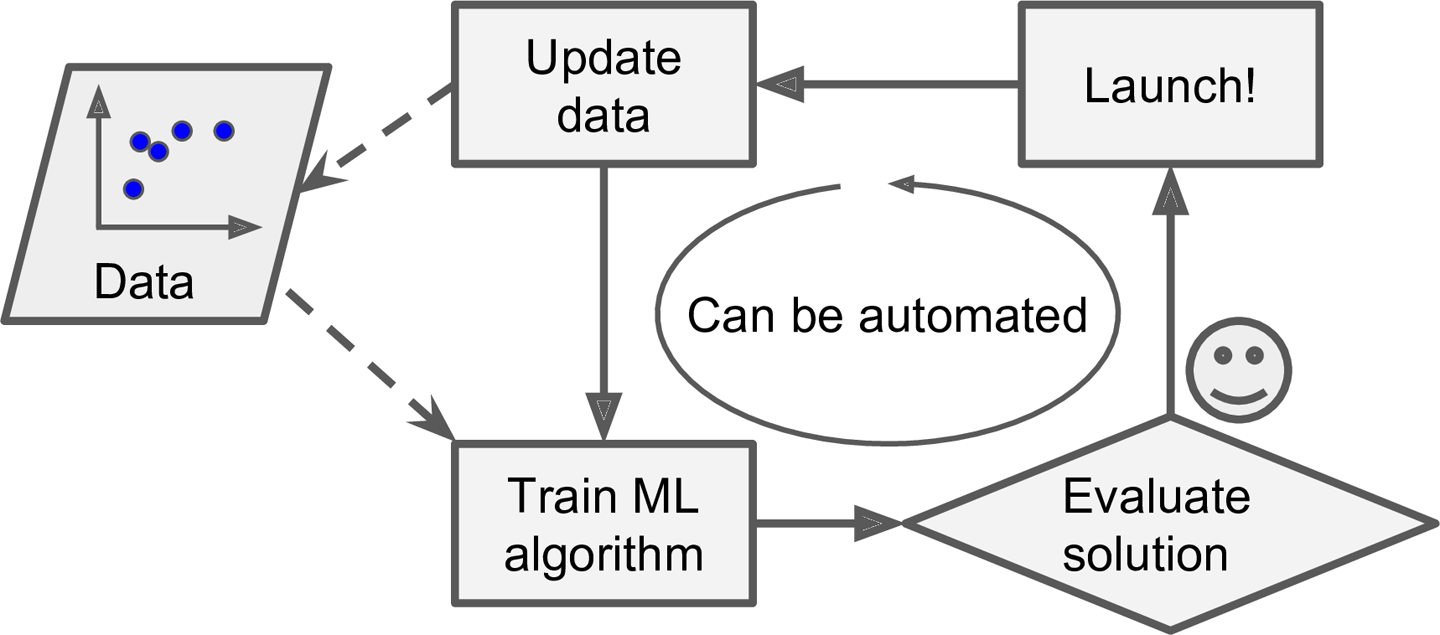
Finalmente, a solução apresentada pelo algoritmo treinado pode trazer novas ideias sobre como resolver o problema, encontrando correlações desconhecidas por exemplo.
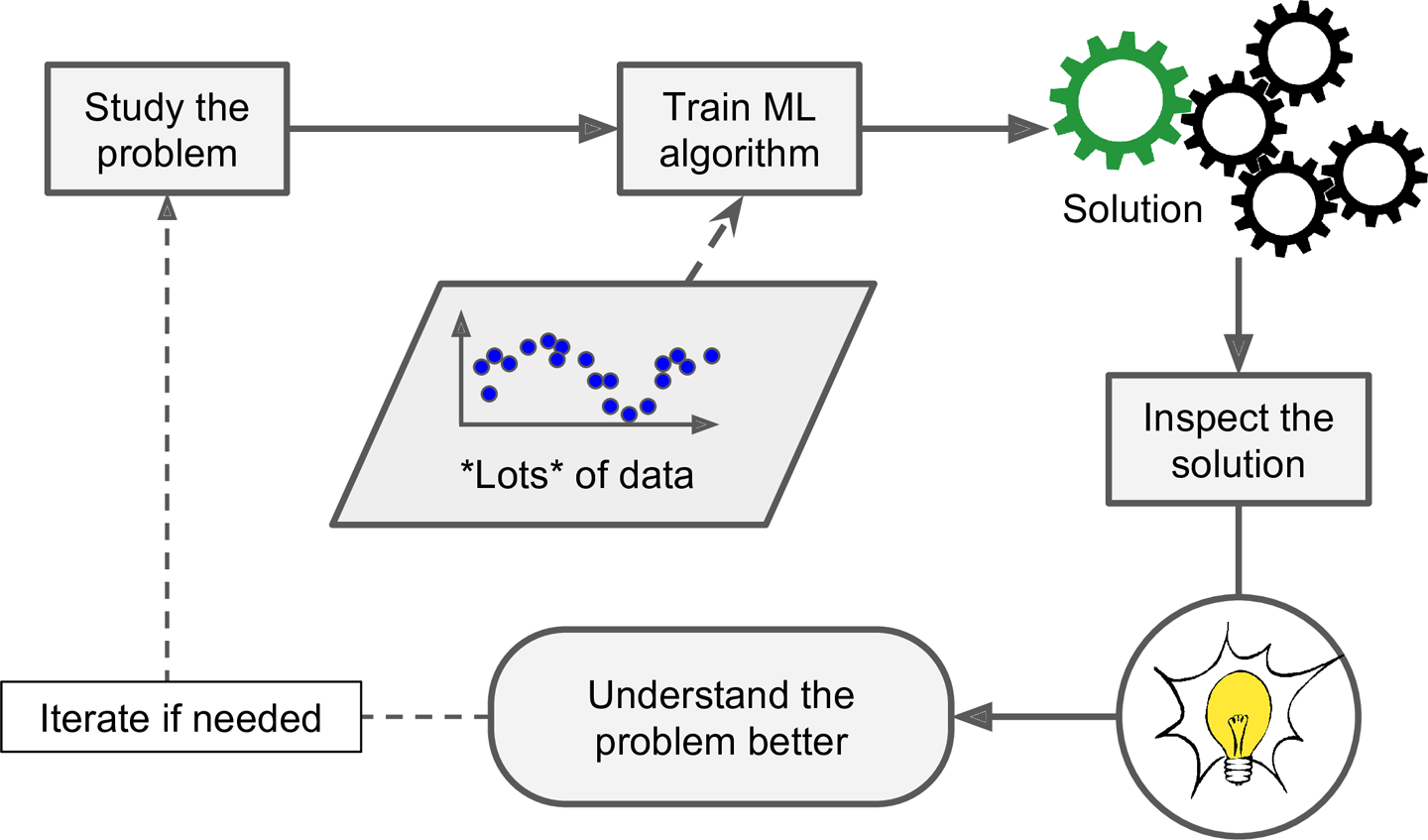
Tipos de Sistemas do Aprendizado de Máquina
O livro de Aurélien Géron classifica os sistema de aprendizado de máquina com base nas seguintes categorias:
- Em que nível têm supervisão humana
- supervisionado,
- não supervisionado,
- semi-supervisionado,
- aprendizado por reforço.
- Se podem aprender de forma incremental, enquanto funciona, ou se precisa ser treinado de uma vez para depois ser colocado em prática.
- aprendizado online (aprender enquanto funciona)
- aprendizado por lotes (é treinado uma vez para depois funcionar)
- Se apenas fazem comparação com dados de entrada; ou se criam um modelo para fazer predição
- aprendizado baseado em instâncias,
- aprendizado baseado em modelos.
Aprendizados Supervisionados ou Não
Aprendizado Supervisionado
Em um aprendizado supervisionado você tem um conjunto de dados rotulados (labels) com a solução desejada.
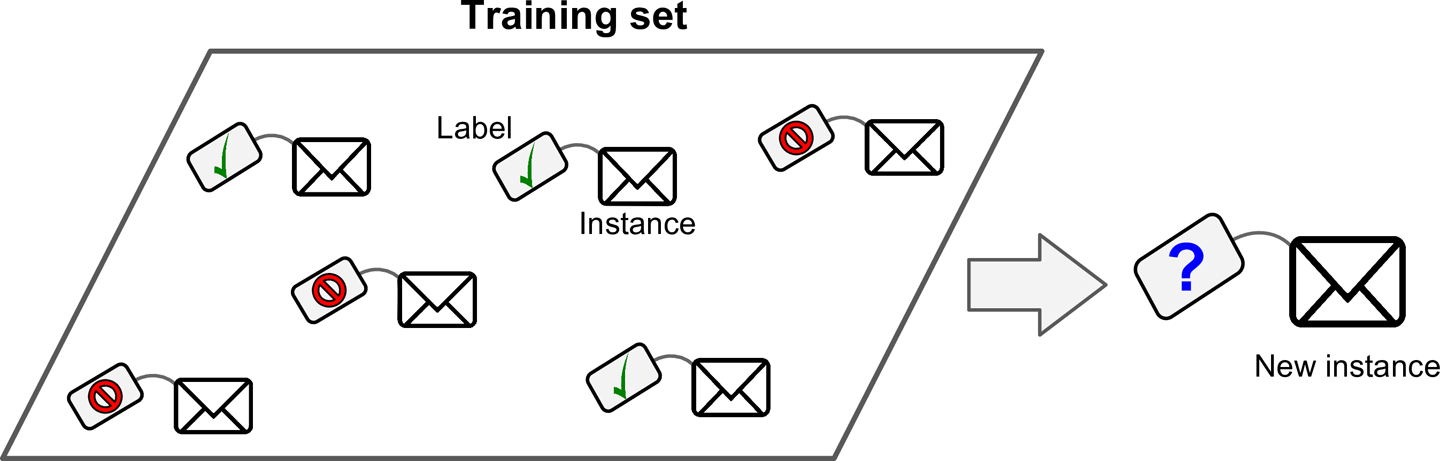
A figura acima representa o problema de filtro de spam, um problema de classificação.
O conjunto de treinamento recebe vários emails rotulados como "spam" ou "não spam". O algoritmo aprende com este conjunto durante a fazer de treinamento.
Um outro problema clássico supervisionado é o problema de regressão. Onde o algoritmo precisa descobrir o valor de um campo em um dado de entrada. Depois de passar por um treinamento com valores dados.
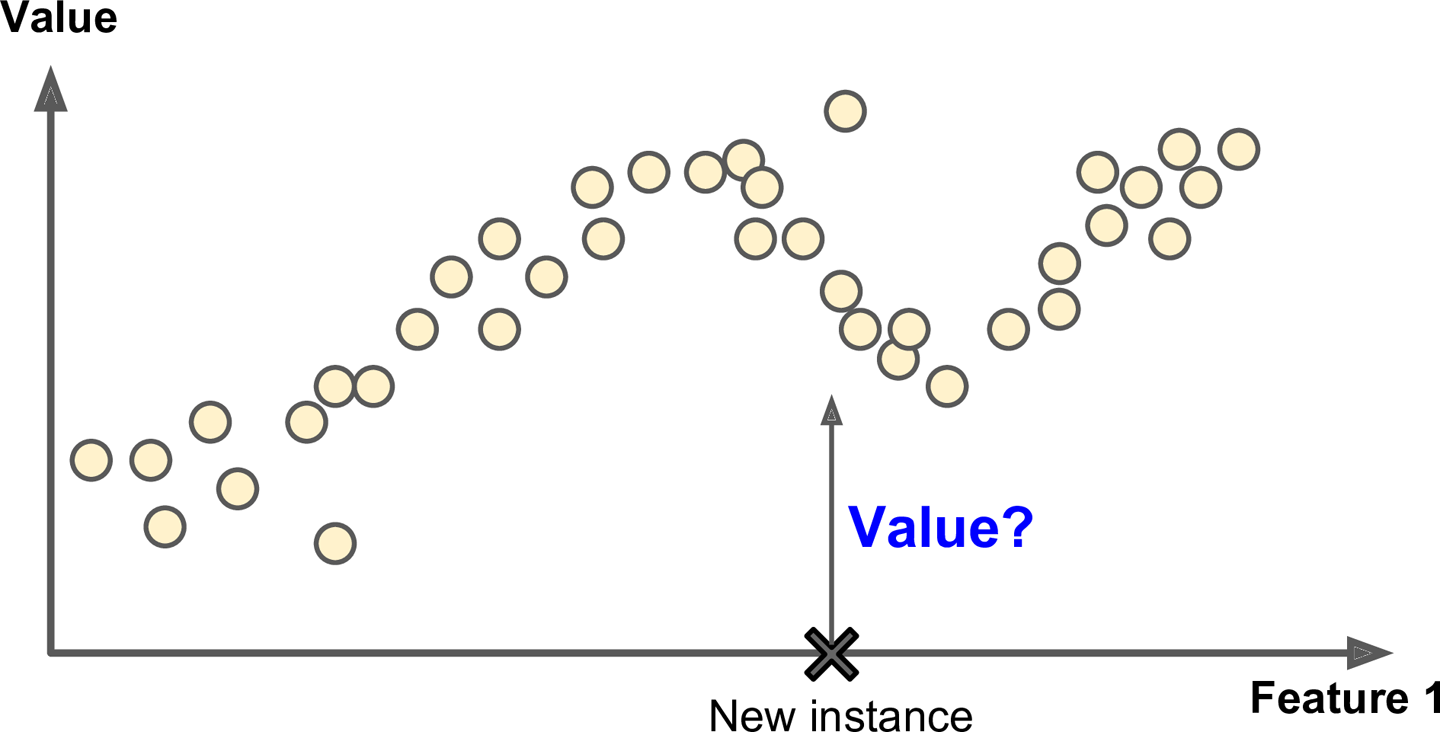
Um exemplo é descobrir qual é o preço de um carro, usando características como ano, marca, quilometragem, quantidade de portas, etc...
O algoritmo recebe uma alta quantidade de dados de carros com o preço incluído para a parte de treinamento. Depois esperasse que o algoritmo consiga acertar o preço de novos dados de carros, baseado em suas outras características.
Aprendizado Não-Supervisionado
Em um aprendizado não supervisionado os dados de entrada não são rotulados.
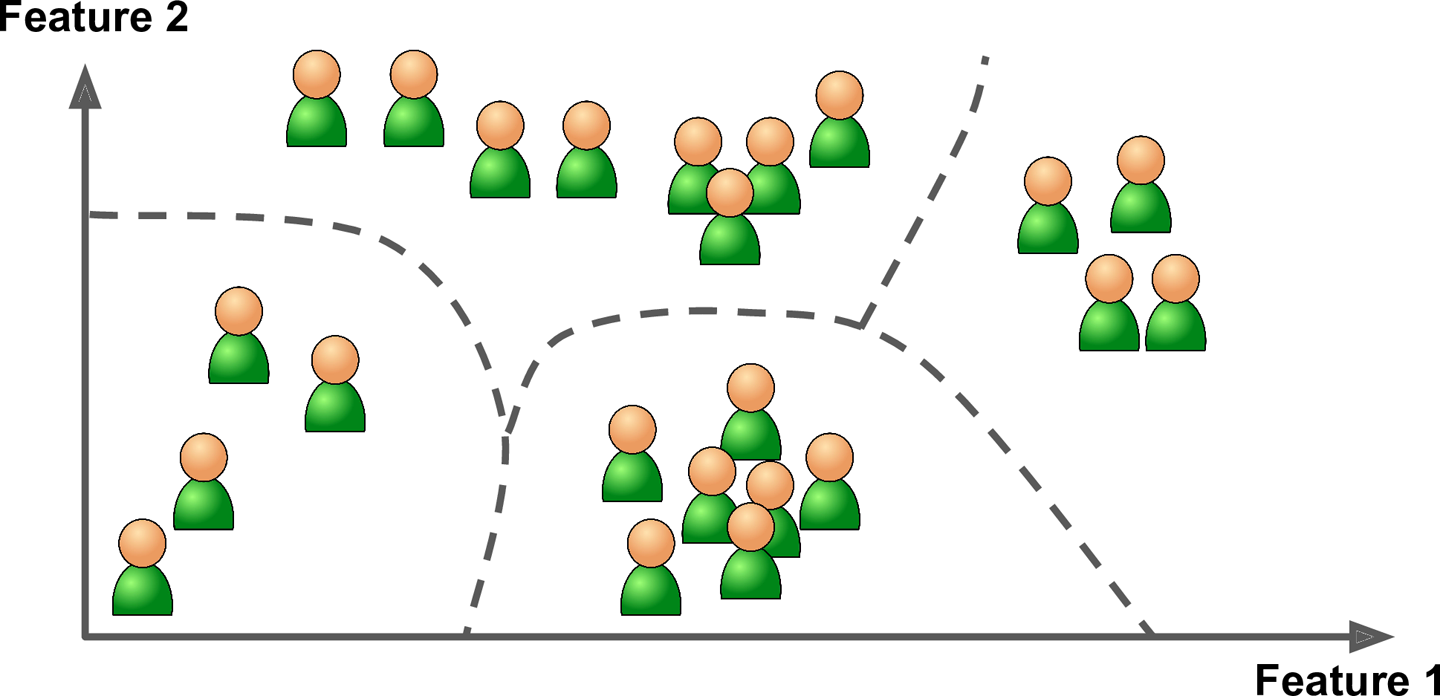
O sistema pode receber o conjunto representado pela seguinte figura e ser pedido para dividir o grupo em 4 grupos.

Usando as características dadas por cada elemento, ele pode dividir como na figura abaixo.
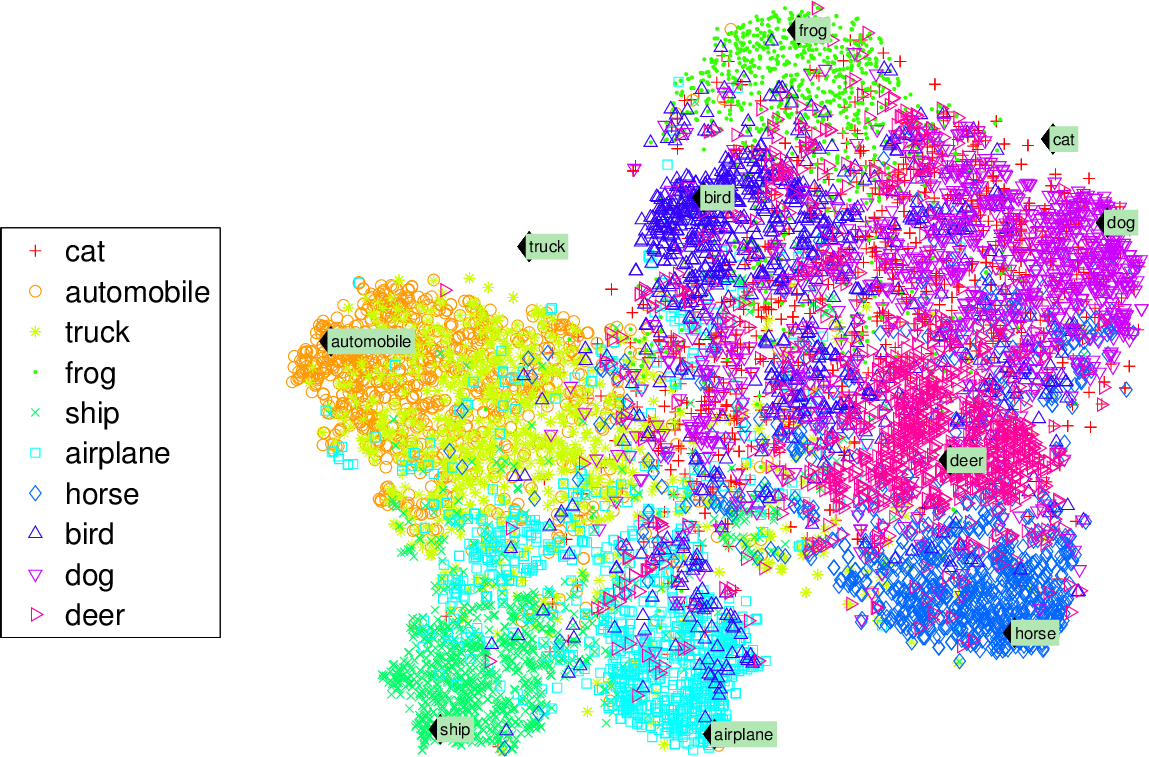
Uma visualização de dados de agrupamento pode ser dada pela figura abaixo.
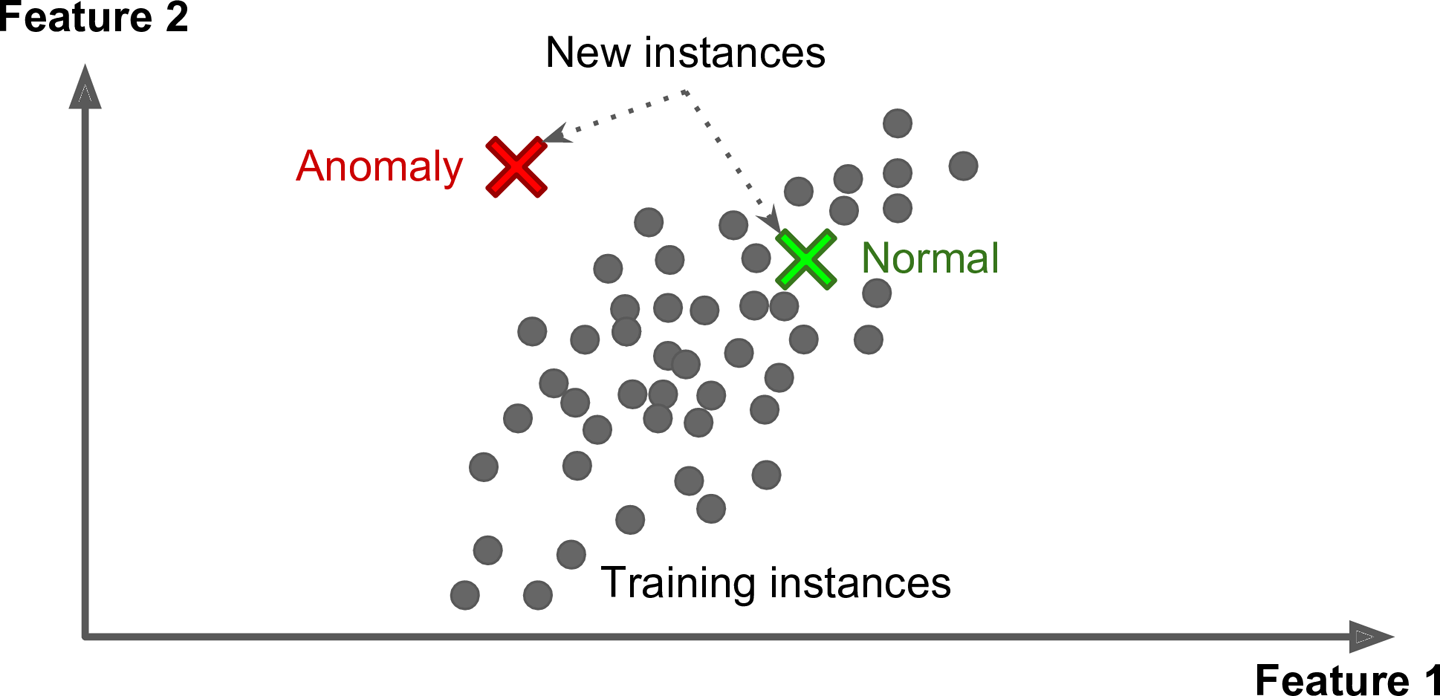
Um outro problema importante é a detecção de anomalias. Um conjunto de treinamento é dado para o algoritmo, e qualquer coisa que escape muito do conjunto será tratado como anomalia.
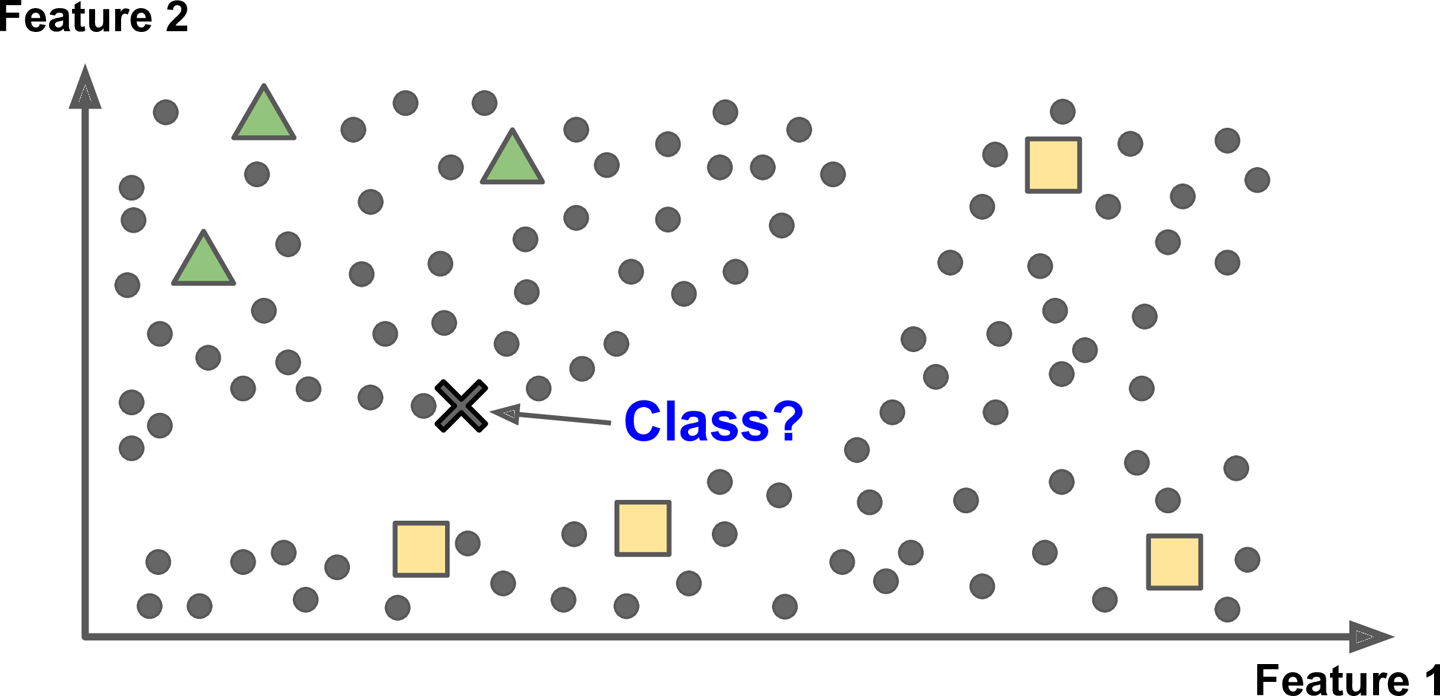
Aprendizado Semi-Supervisionado
No conjunto de treinamento de um aprendizado semi-supervisionado você terá apenas alguns elementos com rótulos
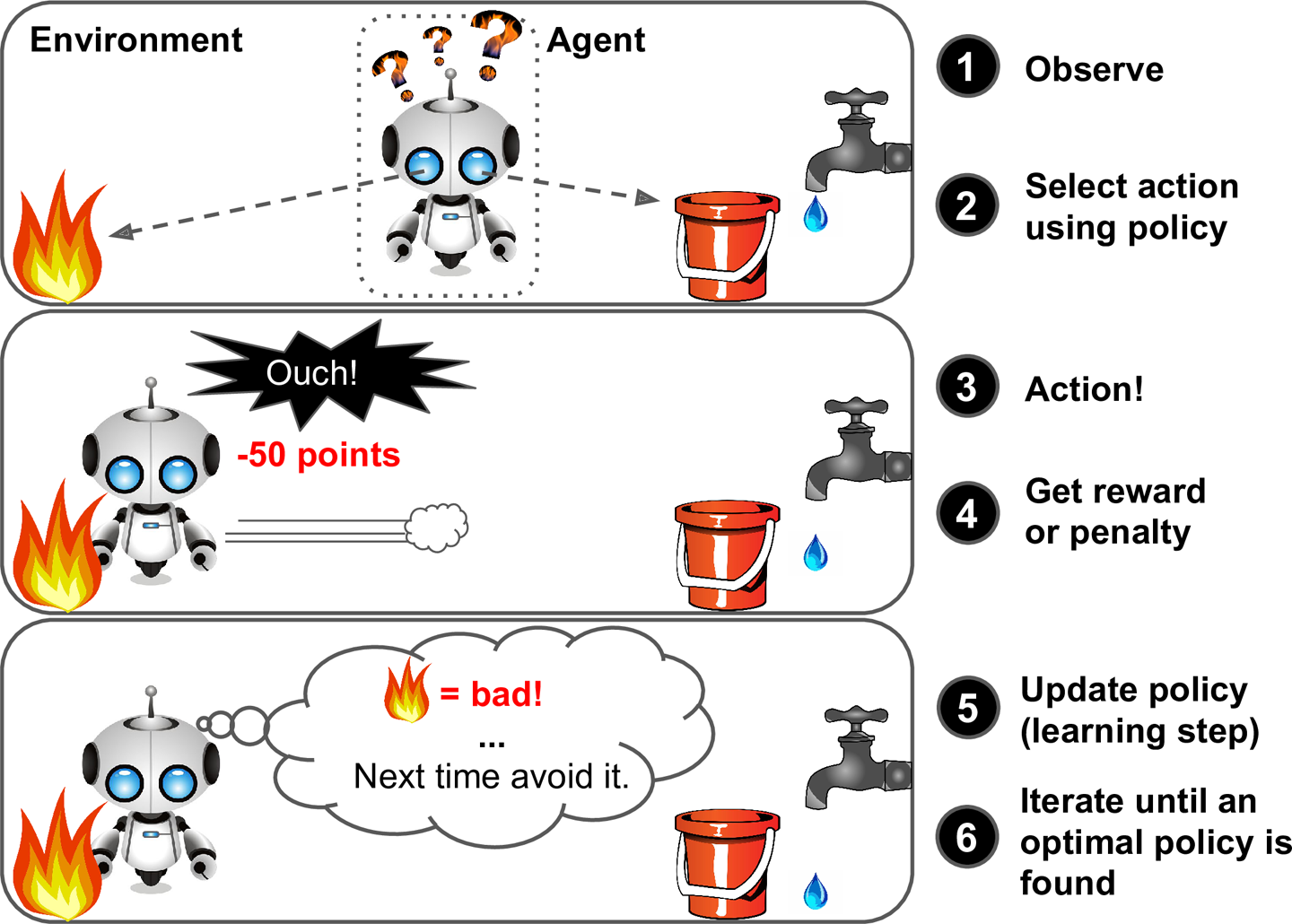
Aprendizado Por Reforço
Em um aprendizado por reforço o sistema pode observar o ambiente, tomar decisões e executar ações.
Um sistema de recompensa ou penalidade irá condicionar o sistema a tomar as melhores decisões.
Aprendizado em Lote ou Online
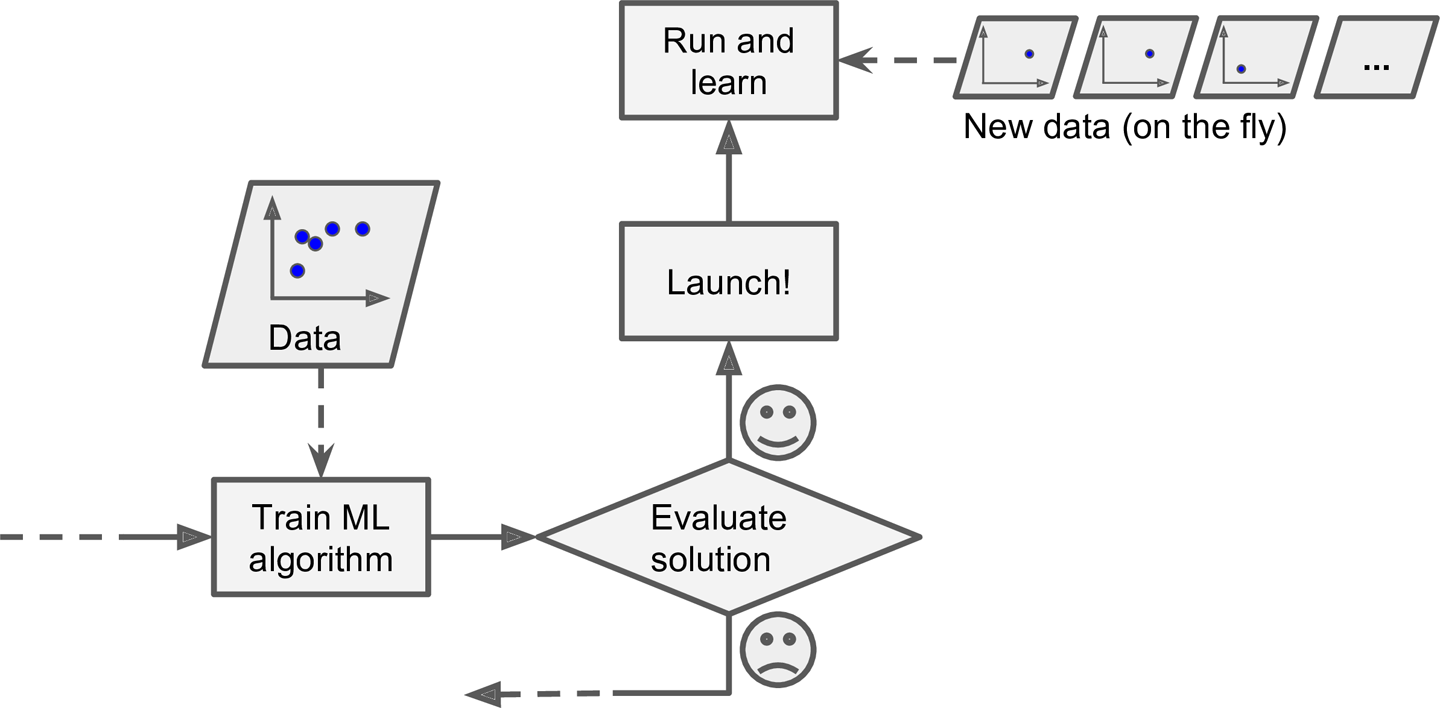
Aprendizado em Lote (offline)
No Aprendizado em Lote (também conhecido como offline) o sistema é treinado com todos os dados disponíveis e depois é lançado para produção, sem aprender mais nada após ser lançado.
Isto não quer dizer que o sistema não será atualizado. Você pode adquirir novos dados, treinar novamente o sistema e depois lançar uma atualização para produção. Mas o sistema que está em produção não aprenderá enquanto em produção.
O aprendizado em lotes é usado para sistemas que demandam muito poder de processamento na fase de treinamento, não podendo usar este poder em produção.
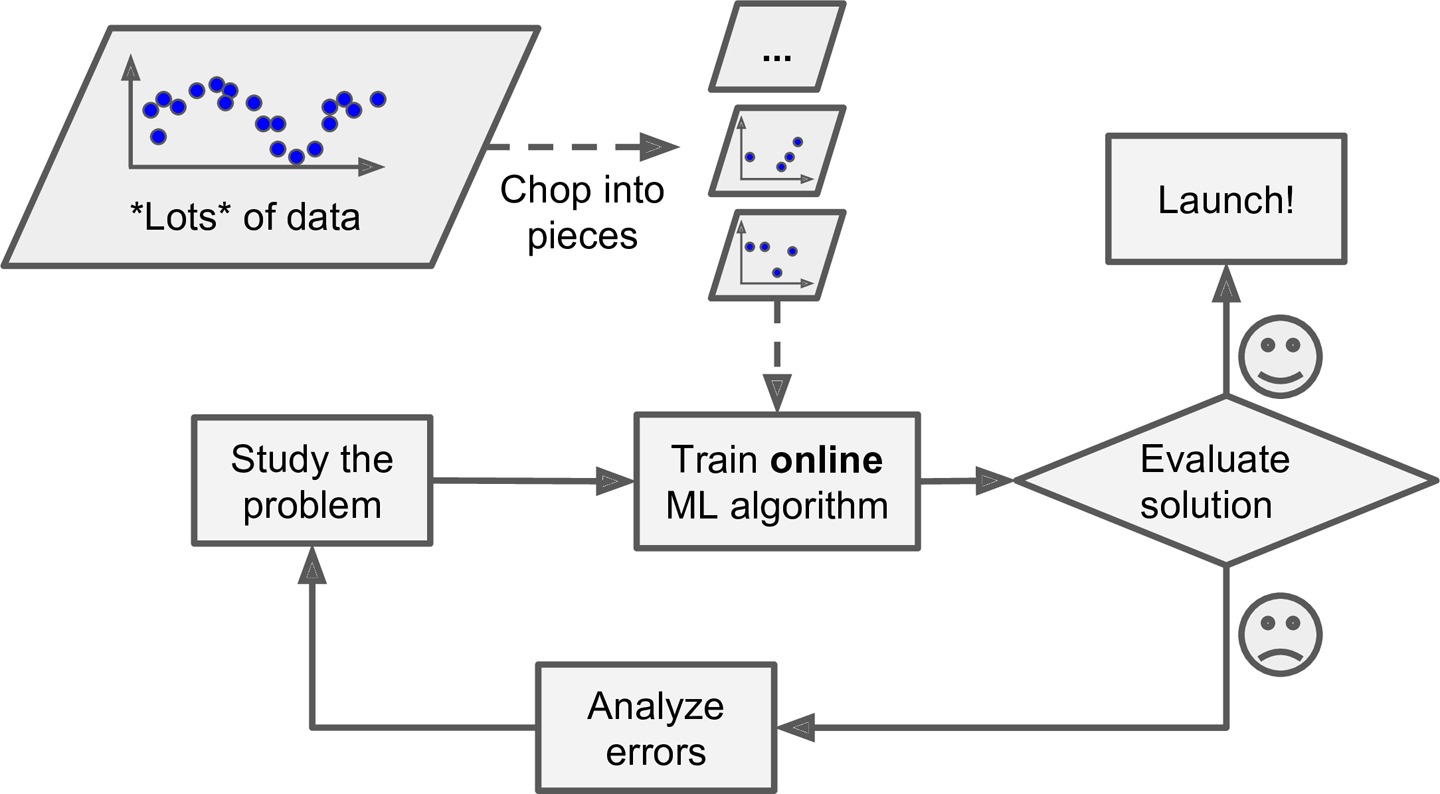
Aprendizado Online
No aprendizado online o sistema pode ser treinado antes de ser lançado, mas também continuará aprendendo enquanto funciona.
O aprendizado online é usado para sistemas que devem se adaptar enquanto rodam e perceber mudanças em tempo real. Um exemplo é prever preço de ações na bolsa de valores, ou fazer recomendações de produtos para usuários de sites de compras.
Um outro uso do sistema online é quando você tem que usar muitos dados para treinar o sistema, mais dados do que acaberiam na memória. Nestes casos você pode separar os dados em pequenos pedaços e treinar o sistema com cada pedaço dos dados, como se tivesse em produção.
Aprendizado Baseado em Instância vs Aprendizado Baseado em Modelo
Aprendizado Baseado em Instância
Imagine que você esteja fazendo o filtro de spam e resolva fazer um sistema que marca como spam apenas os emails que são idênticos aos spams já conhecidos. Ou melhor, todos os emails que têm algum alto grau de semelhança.
Neste caso, o sistema não está tentando modelar um padrão, está apenas marcando objetos semelhantes ao que já tem por meio de memorização. Isso é chamdo de aprendizado em instância.
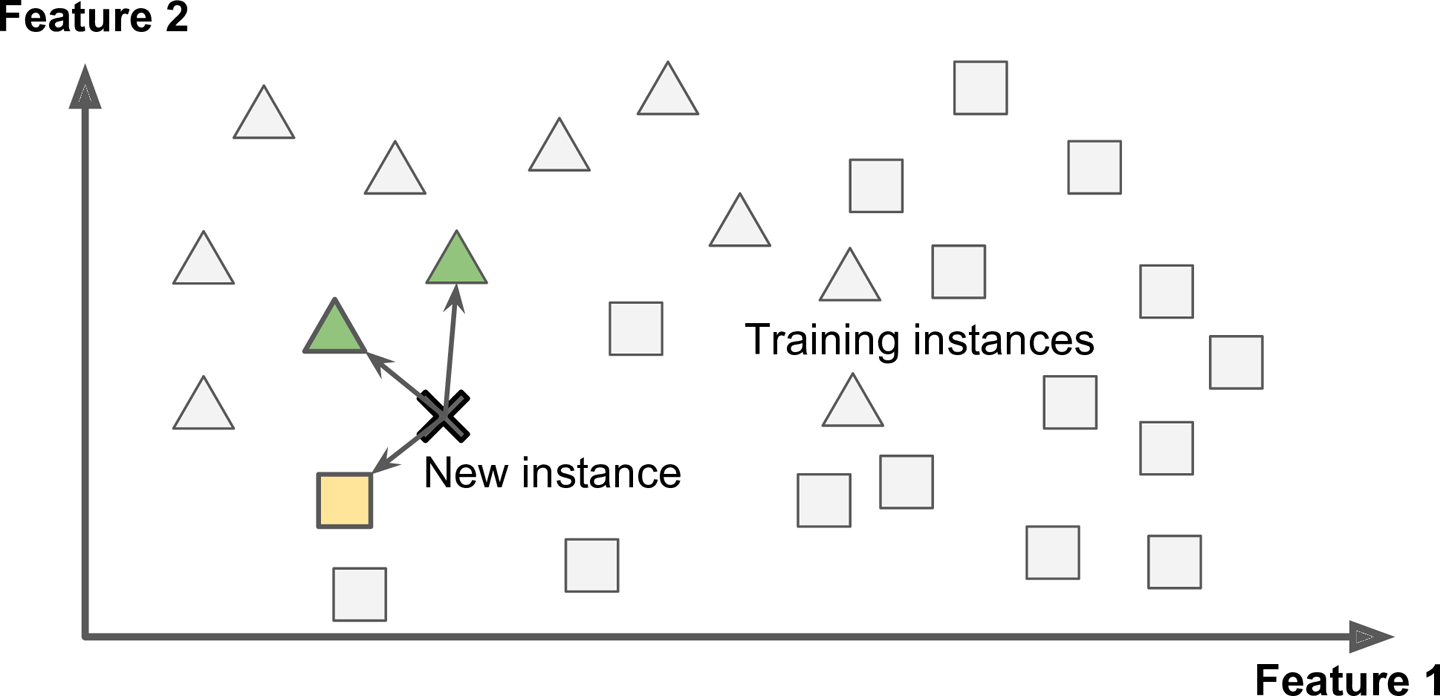
Aprendizado Baseado em Modelo
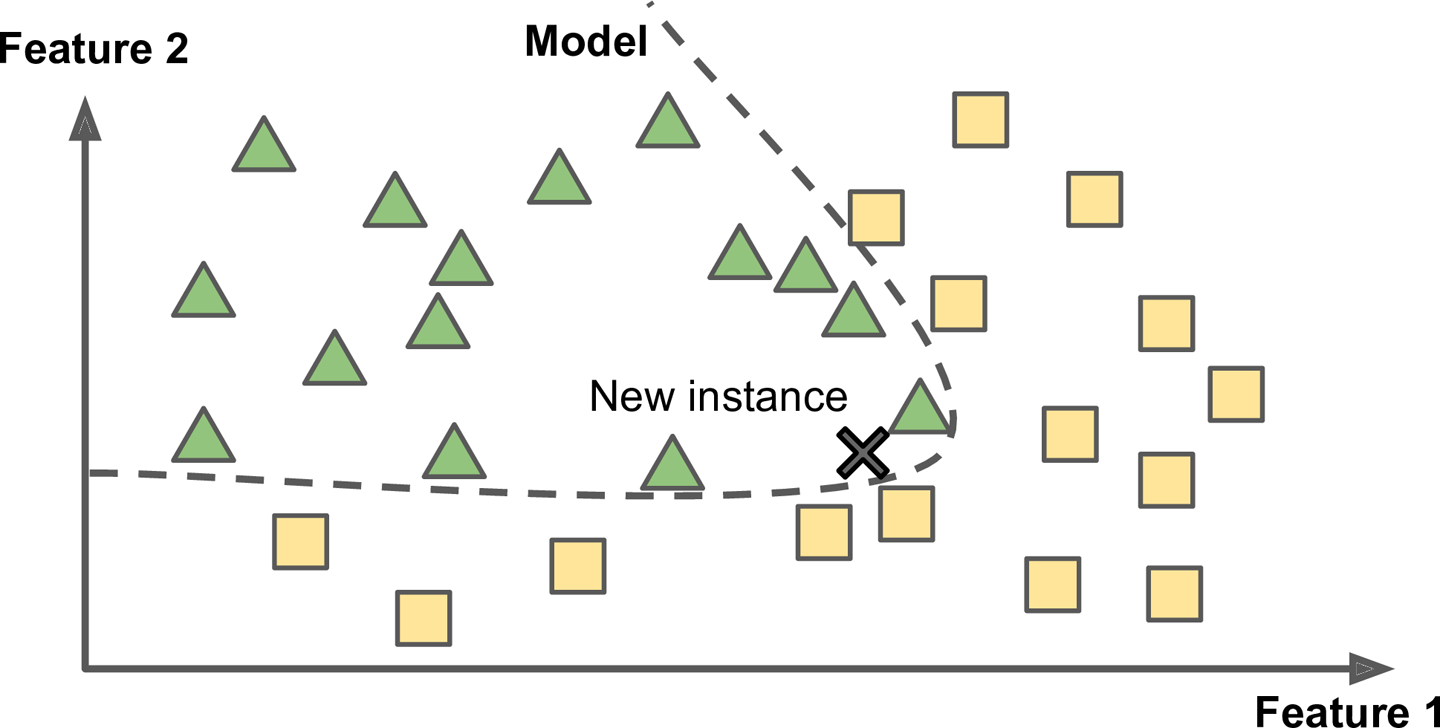
Um outra maneira de treinar o sistema é fazê-lo tentar modelar um padrão.
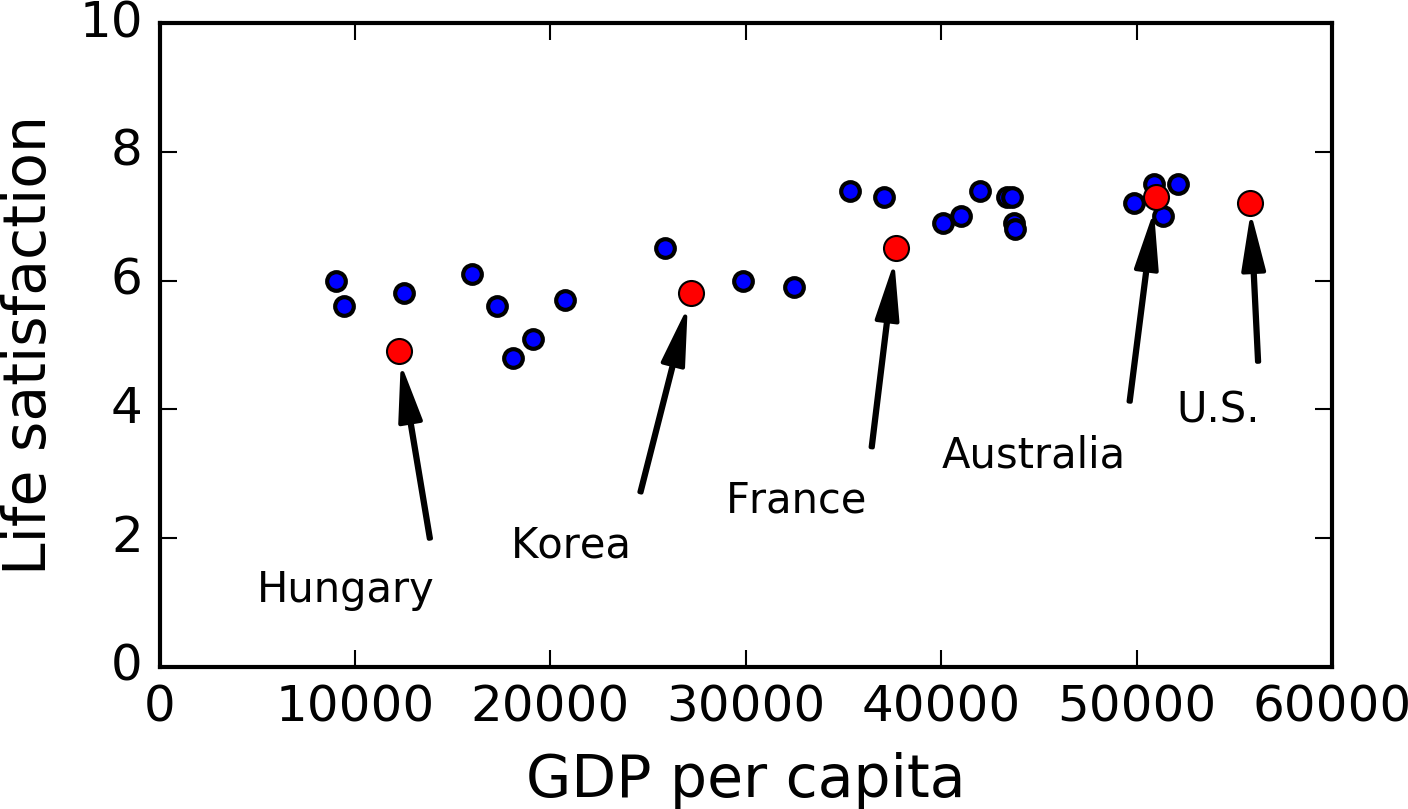
Imagine que você esteja tentando prever o PIB per capita baseado na satisfação de vida (ou vice versa) de um país e tenha os seguintes dados:
Você pode tentar fazer o sistema encontrar a equação linear que, dado uma característica, irá prever a outra:
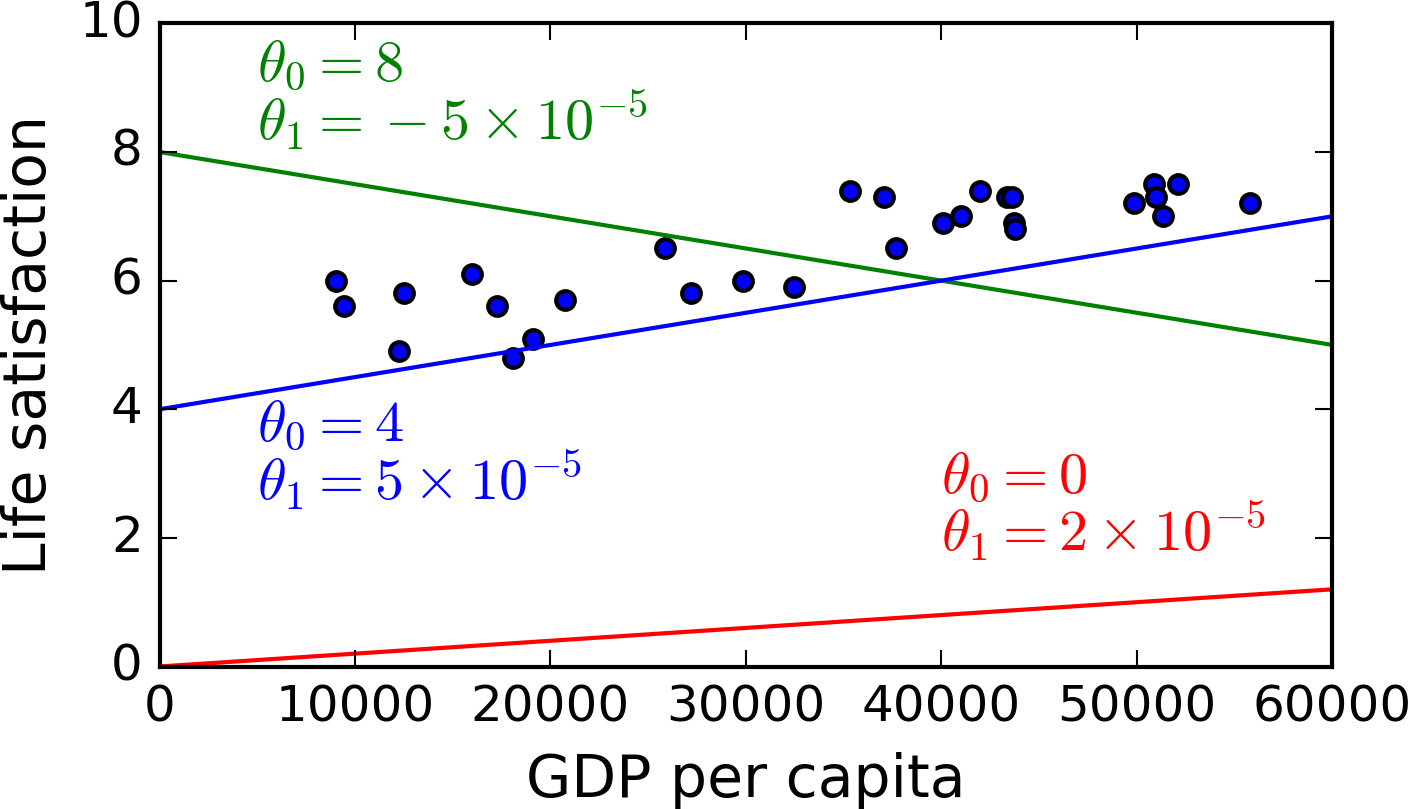
Possibilidades de equações lineares
Após treinado o seu sistema chega à seguinte equação:
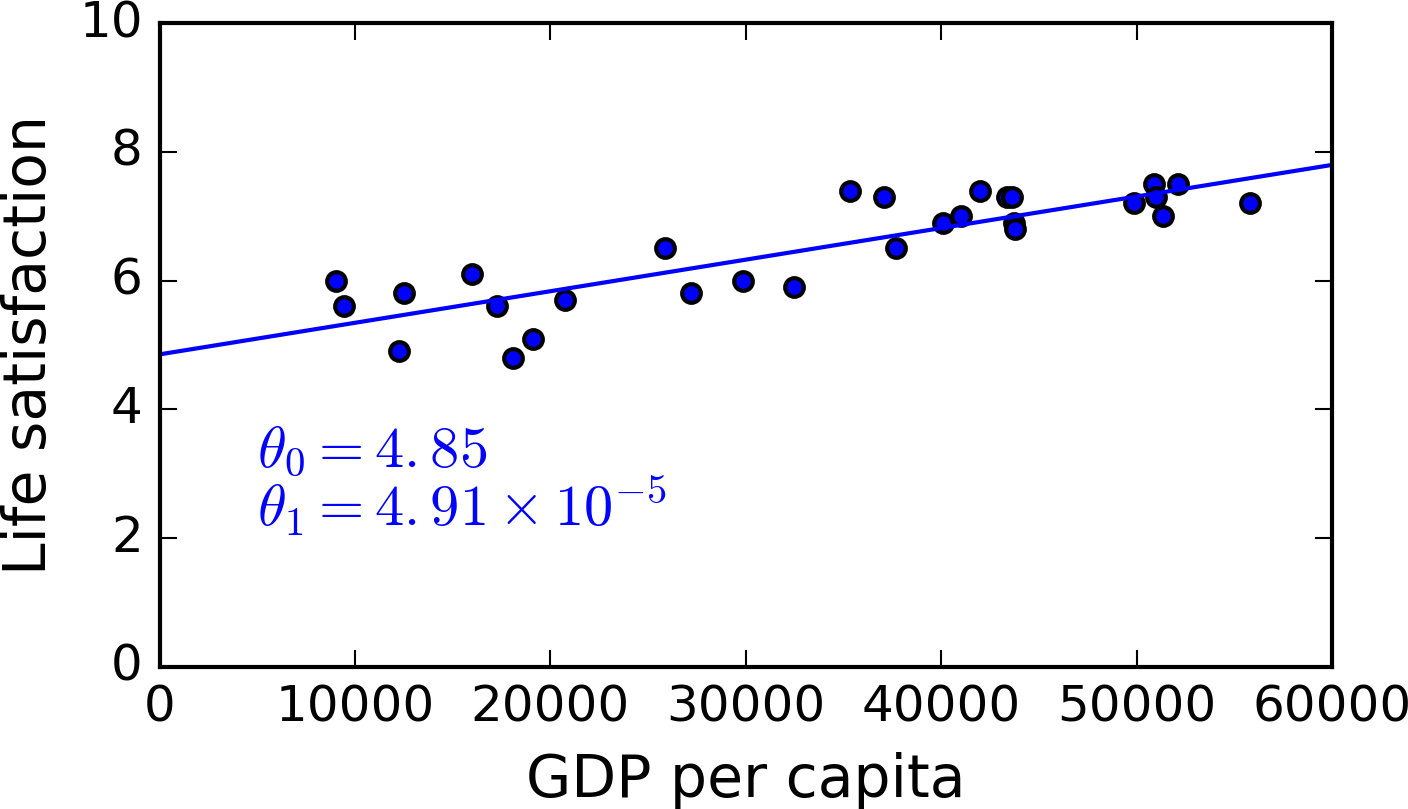
A equação será a equação que irá modelar o sistema para prever a resposta.
.
Esta aula usou como referência o livro Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow e a tradução Mãos à Obra: Aprendizado de Máquina com Scikit-Learn & TensorFlow. ↩︎
O capítulo usado nesta aula pode ser encontrado através deste link. ↩︎